SSE and AVX Mutation Idea (xlate)
Table of contents
SSE and AVX Mutation Idea (xlate)
All Streaming SIMD Extensions (SSE) instructions using legacy encoding can be translated to Advanced Vector Extensions (AVX) encoding. This is already something that most compilers offer these days when using the correct compilation flag (i.e., -QxAVX with MSVC) to compile all legacy SSE instructions into their AVX counterpart.
Compilers will mostly do that for optimisation reason; however, in our case, this is not necessarily what we are looking for. What is more interesting is to be able to modify the encoding of instructions whilst not modifying their operands and the result of their execution. For this very reason a module for a mutation engine could be developed to translate all legacy SSE instructions to AVX format or from AVX to Legacy SSE format to modify the signature of a piece of code.
Therefore, the objective of this paper is to shortly discuss what SSE and AVX are and how it is possible to switch from one format to another without too many difficulties.
Streaming SIMD Extensions (SSE)
Before SSE there was the MMX facilities. The MMX facilities is the first to implement the concept of Single-Instruction, Multiple Data (SIMD), an instruction set that can perform arithmetic and logical operations on multiple data (i.e., bytes, words, or dwords) – hence the name SIMD. The goal being to reduce memory access operations which take a lot of time to process. This is quite useful for modern media, communication and graphic applications.
Example of SIMD operation: addss xmm1,xmm2
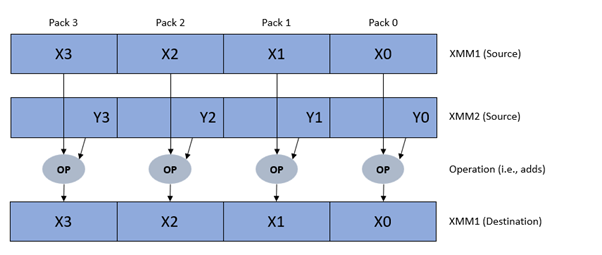
However, MMX data registers are aliases for the low 64-bit part of the x87 FP data registers (i.e., ST(0) – ST(7)) on top of limitations or edge cases when a routine uses both instruction sets (e.g., data lose and performance issues). Additionally, MMX facilities does not support operations on floating point values.
This is what the first version of the SSE facilities tries to address via new SIMD and non-SIMD instructions. Also, with it comes completely new 128-bit data registers (i.e., XMM0 – XMM7) which can be used to operate on scalar (single integer/FP for non-SIMD) or packed (for SIMD) operands, such as:
- 16 bytes packed integers
- 8 words packed integers
- 4 dwords packed integers
- 2 qword packed integers
- 4 single-precision (SP) floating point
- 2 double-precision (DP) floating point
Other features have been implemented such as:
- Enhancement of specific type of memory write operation on cacheable memory via Non-Temporal stores (streaming stores) instructions, for example:
MOVNTPS,MOVNTQ, orMASKMOVQ; - Video and media-specific instructions, for example:
PAVD,LDDQU; - Thread synchronisation instructions, for example:
PAUSE,MONITOR,MWAIT; and - Legacy prefix branch hints to help with misprediction when dealing with conditional branches.
Requesting the feature flags via the CPUID instruction can be used to identify whether a specific SSE instruction set is available.
| Instruction Set | Introduced With | Year | Number of Instructions | CPUID Flag | Register |
|---|---|---|---|---|---|
| SSE | Pentium III | 1999 | 70 | 002000000h | EDX |
| SSE2 | 130nm Pentium 4 | 2002 | 114 | 004000000h | EDX |
| SSE3 | 90nm Pentium 4 | 2004 | 13 | 000000001h | ECX |
| SSsE3 | Core 2 Duo | 2006 | 32 | 000000200h | ECX |
| SSE4.1 | 45nm Core 2 Duo (Penryn) | 2008 | 47 | 000080000h | ECX |
| SSE4.2 | Core i7 (Nehalem) | 2008 | 7 | 000100000h | ECX |
Simple MASM code that can be used in conjunction with the above table, example for SSE:
SSESupport PROC
xor eax, eax
inc eax
cpuid
and edx, 002000000h
shr edx, 19h
xchg eax, edx
ret
SSESupport ENDP
Advanced Vector Extensions (AVX)
Introduced with Sandy Bridge (Q1 2011) Intel processors, the AVX facilities continue to enhance SIMD functionalities and offers new features such as:
- New 256-bit data register (i.e., YMM0 – YMM7) with the lowest 128-bit being aliases for XMM data registers.
- New encoding with the new 2- or 3-byte VEX prefix for legacy SSE instructions and new AVX instructions; and
- Non-destructive operand operations to reduce the number of copies and load operations; and
- Up to three source operands (with 4 operands instructions) using the upper 4-bit of a 8-bit immediate data value (i.e.,
VEX[vvvv]+ModRM[rm]+ModRM[reg]+imm8[7:4]).
Note that for this very paper there I will not go too much into AVX2 and I will not cover AVX-256 and Fused-Multiply-Add (FMA) extensions, which brings even more functionalities. Also, with AVX-256 another encoding is possible with the EVEX prefix (i.e., replacement of VEX).
Before being able to use AVX it is important to check that both the processor and the operating system does support the AVX instruction set and 256- and 128-bit data registers. The following MASM code can be used to check the aforementioned from either User-Mode (UM) or Kernel-Mode (KM):
AVXSupport PROC
; Get features flags
xor eax, eax
inc eax
cpuid
mov eax, ecx
mov ebx, ecx
; Check for OSXSAVE and AVX support
and eax, 008000000h
shr eax, 1Bh
and ebx, 010000000H
shr ebx, 1Ch
; Get return value
and al, bl
jz return
get_xcr0:
xor ecx, ecx
XGETBV
mov ebx, eax
; Check for XMM and YMM registers
and eax, 04h
shr eax, 02h
and ebx, 02h
shr ebx, 01h
; Get return value
and al, bl
return:
ret
AVXSupport ENDP
AVX and the new VEX
As mentioned in the previous section, AVX offers a new way to encode instructions (including legacy SSE) with a compact 2- or 3-byte Vector Extension (VEX) prefix, respectively starting with C5h and C4h bytes. The composition of the 2- and 3-byte VEX prefix can be found in the Intel documentation:
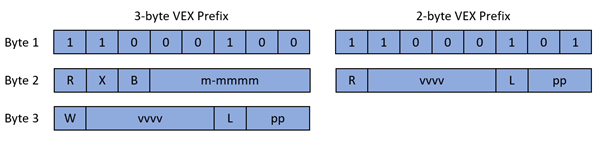
Fields are as follows:
- R: like
REX[R]in 1’s complement (inverted) form:- 1b: Same as
REX[R] = 0b(must be set to this in 32-bit mode otherwise LES/LDS) - 0b: Same as
REX[R] = 1b(64-bit mode only)
- 1b: Same as
- X: Like
REX[X]in 1’s compliment (inverted) form:- 1b: Same as
REX[X] = 0b(must be set to this in 32-bit mode otherwise LES/LDS) - 0b: Same as
REX[X] = 1b(64-bit mode only)
- 1b: Same as
- B: Like
REX[B]in 1’s compliment (inverted) form:- 1b: Same as
REX[B] = 1b(ignored in 32-bit mode) - 0b: Same as
REX[B] = 0b(64-bit mode only)
- 1b: Same as
- W: This can either be used like
REX[W]or as an additional escape extension. This will be opcode specific. - m-mmmm: Used to specify opcode escape sequence (will always be 0Fh when using 2-byte VEX prefix):
- 00000b: Reserved and will
#UD - 00001b: Implied 0Fh escape opcode (Table 2)
- 00010b: Implied 0F38h escape opcodes (Table 3)
- 00011b: Implied 0F3Ah escape opcodes (Table 4)
- 00100b-11111b: Reserved will
#UD
- 00000b: Reserved and will
- vvvv: Used in conjunction with a ModRM byte to specify an additional register as source or destination. This is encoded in 1’s complement form (inverted) or 1111b if unused:
- 1111b: XMM0/YMM0
- 1110b: XMM1/YMM1
- 1101b: XMM2/YMM2
- 1100b: XMM3/YMM3
- 1011b: XMM4/YMM4
- 1010b: XMM5/YMM5
- 1001b: XMM6/YMM6
- 1000b: XMM7/YMM7
- 0111b: XMM8/YMM8
- 0110b: XMM9/YMM9
- 0101b: XMM10/YMM10
- 0100b: XMM11/YMM11
- 0011b: XMM12/YMM12
- 0010b: XMM13/YMM13
- 0001b: XMM14/YMM14
- 0000b: XMM15/YMM15
- L: Vector length bit used to promote operands to 256-bit:
- 0b: scalar or 128-bit vector operand
- 1b: 256-bit vector operand
- pp: Specify a SIMD prefix used as an additional escape opcode:
- 00b: None
- 01b: 66h
- 10b: F3h
- 11b: F2h
Additionally, for a very small subset of AVX2 instructions, a new Vector SIB (VSIB) byte can be used for memory addressing. This is a special case that will not be discussed there. You can find the list of AVX instructions encoded with a VEX prefix that do uses a VSIB byte later in this paper.
Finally, like all the other prefixes (e.g., Operand Size Override or REX), VEX must be positioned before the primary opcode. Additionally, as shown in the above schema, VEX has bit fields equivalent to the REX prefix, to encode escape opcodes (i.e.,0Fh, 0F38h and 0F3Ah) and SIMD prefixes (i.e., 66h, F2h and F3h). Therefore, if any of them are used with a VEX prefix, an Undefined Instruction (i.e., #UD) exception will be raised.
Translation between Legacy SSE to AVX
As aforementioned, all legacy SSE instructions can be converted into AVX format. However, it does not mean that all AVX instructions can be encoded in legacy SSE format. Over the years SSE has been deprecated and newest instructions can only be encoded using VEX (or EVEX if we consider AVX-512).
Additionally, there is three things to be careful about when translating instructions:
- First, some instructions when encoded via VEX uses an additional non-destructive (ND) operand to limit the number of read/write access to/from registers and memory addresses. It means that the ND operand which is encoded with
VEX[vvvv]needs to be interpreted. Note that this ND operand can be either a source or a destination; however, only a subset on AVX instructions (13) usesVEX[vvvv]as a destination operand (1st operand) and only AVX2 instructions using VSIB byte and few others uses (13)VEX[vvvv]as a second source operand (3rd operand). - Second, again, some AVX instructions does not exist in a legacy encoding format (lot of AVX2 and all AVX-512). Therefore, attending to encode them in a legacy format will produce nonsense at best or
#UD - Thirdly, any AVX instructions operating on 256-bit operands (i.e.,
VEX[L] = 1b) cannot be encoded in legacy SSE format because of the data limitation of the XMM data registers (i.e., 128-bits).
Later in this paper the lists of instructions using an additional non-destructive operand and AVX only instructions are provided. There is also the list of AVX2 instructions using VSIB for vector memory access addressing.
Example 1: Basic 2-byte VEX Encoded Instruction
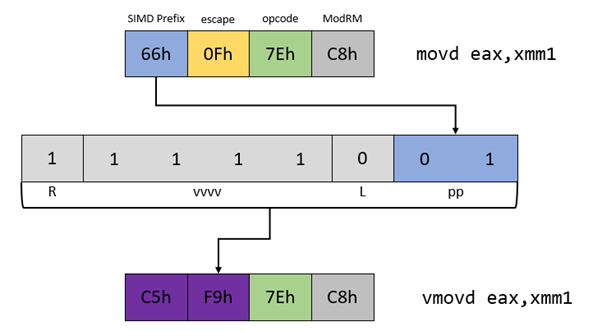
| Mnemonic | Operands | Encoding |
|---|---|---|
| MOVD | r/m32, xmm | 66 0F 7E /r |
| VMOVD | r/m32, xmm | VEX.128.66.0F.W0 7E /r |
2-byte VEX prefix will be used because no non-destructive additional register is required, the general-purpose data register do not need to be promoted to 64-bit, and, the instruction operates on 128-bit XMM register. Elements to consider:
- SIMD prefix
66h:VEX[pp] = 01b - Escape opcode
0Fh: implied with a 2-byte VEX prefix - 64-bit register promotion
W0:VEX[W] = 0b(not used in 2-byte VEX version) - 128-bit only operands:
VEX[L] = 0b
Example 2: Basic 3-byte VEX Encoded Instruction with 64-bit
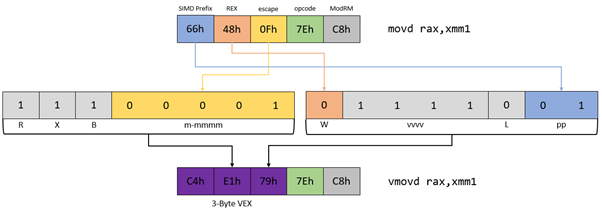
| Mnemonic | Operands | Encoding |
|---|---|---|
| MOVDQ | r64/m64, xmm1 | 66 REX.W 0F 7E /r |
| VMOVDQ | r64/m64, xmm1 | VEX.128.66.0F.W1 7E /r |
3-byte VEX prefix will be used because the general-purpose data register DO need to be promoted to 64-bit. Even if non-destructive additional register is required and the instruction operates only on 128-bit XMM register. Elements to consider:
- SIMD prefix
66h:VEX[pp] = 01b - Escape opcode
0Fh:VEX[m-mmmm] = 00001b - 64-bit register promotion
W1:VEX[W] = 0b - 128-bit only operands:
VEX[L] = 0b
Example 3: 3-byte VEX Encoded Instruction with SIB

| Mnemonic | Operands | Encoding |
|---|---|---|
| MOVDQ | xmm1, xmm2/m128 | 66 0F D6 /r |
| VMOVDQ | xmm1, xmm2/m128 | VEX.128.66.0F.WIG D6 /r |
Similar instruction as example two but with a SIB byte and an immediate data value. Also, special case when the AVX instruction does not care about VEX[W] bit field (i.e., WIG). Elements to consider:
- SIMD prefix
66h:VEX[pp] = 01b - Escape opcode
0Fh:VEX[m-mmmm] = 00001b - 64-bit base register promotion:
VEX[B] = 0b - 128-bit only operands:
VEX[L] = 0b
Example 4: With Non-Destructive Operand
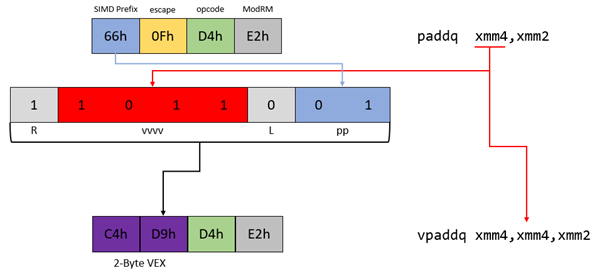
| Mnemonic | Operands | Encoding |
|---|---|---|
| PADDQ | xmm1, xmm2/m128 | 66 0F D4 /r |
| VPADDQ | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F.WIG D4 /r |
In this example there is an instruction using an additional non-destructive operand which will be encoded in the VEX[vvvv] bit field. The complete list of such instruction can be found in one of the tables below. It is important to note that the destination operand need to be encoded twice to prevent unwanted read/write to/from a register or memory address. Elements to consider:
- SIMD prefix
66h:VEX[pp] = 01b - Source operand XMM4:
VEX[vvvv] = 1011b - Escape opcode
0Fh: implied with a 2-byte VEX prefix - 128-bit only operands:
VEX[L] = 0b
WIB and Synonymous Mutation
Some AVX instructions does not care about the state of the VEX[W] bit – it will be ignored. It means that when encoding an AVX instructions with such specification, it is possible to set the bit to either 0 or 1 and therefore generate again another encoding. The modification is small but enough to modify a byte and thus break signature in some cases.
Let’s take for example the following 2 instructions:
C4 C1 79 D6 4C 4A 01 vmovq mmword ptr [r10+rcx*2+1],xmm1
C4 C1 F9 D6 4C 4A 01 vmovq mmword ptr [r10+rcx*2+1],xmm1
In the first version VEX[W] = 0b while on the second version VEX[W] = 1b. Both are valid ways to encode this instruction, will execute and not #UD. Obviously, it will work only when instruction is encoded using 3-byte VEX prefix.
Final Notes
First, when looking at all the examples, it is possible to see that when translating from SSE to AVX or from AVX to SSE encoding the ModRM (and potentially SIB) byte, memory displacement and immediate data value are not affected at all. Only the legacy prefixes used as SIMD prefixes, REX prefix, escape opcode and primary opcodes will be modified, making the whole process easier.
It should be noted that mixing both legacy SSE code and AVX is impacting badly the performances of the CPU. AVX modify the upper bits of the YMM data registers while Legacy SSE instructions cannot modify them. As a result, the upper bits can be in a clean, modified and unsaved (also known as dirty), or preserved/Non_INIT state. As a result, when executing an SSE instruction after an AVX instruction, and vis versa, the processor need to save the state of the register (equivalent to a XSAVE instruction).
Therefore, if different code block can be identified, the VZEROUPPER instruction should be executed before and after executing AVX instructions to clean the upper bits of the YMM registers and set them in a clean mode.
To assite in the understanding of this paper, the following resources can be consulted:
- Volume 1: Basic Architecture - Chapter 10: Programming with Intel Streaming SIMD Extensions (Intel SSE)
- Volume 1: Basic Architecture - Chapter 14: Programming with AVX, FMA and AVX2
- Volume 2: Instruction Set Reference, A-Z - 2.1 Instruction Format for Protected Mode, Real-Address Mode, and Virtual-8086 Mode
- Volume 2: Instruction Set Reference, A-Z - 2.2 IA-32e Mode
- Volume 2: Instruction Set Reference, A-Z - 2.3 Intel Advanced Vector Extensions (Intel AVX)
- Chapter 11: Optimization for Intel AVX, FMA and AVX2 - 11.3 Mixing AVX Code with SSE Code
Appendix A : Non-Destructive Operands Instructions
The table below list all the instructions that can be directly translated from AVX VEX encoding to legacy SSE and from legacy SSE encoding to AVX VEX.
| Type | Mnemonic | Oprands | Legacy Encoding | VEX Encoding | Description |
|---|---|---|---|---|---|
| SSE | COMISS | xmm1, xmm2/m32 | 0F 2F /r | VEX.128.0F.WIG 2F /r | Compare low single-precision floating-point values in xmm1 and xmm2/mem32 and set the EFLAGS flags accordingly. |
| SSE | CVTSS2SI | r32, xmm1/m32 | F3 0F 2D /r | VEX.128.F3.0F.W0 2D /r | Convert one single-precision floating-point value from xmm1/m32 to one signed doubleword integer in r32. |
| SSE | CVTSS2SI | r64, xmm1/m32 | F3 REX.W 0F 2D /r | VEX.128.F3.0F.W1 2D /r | Convert one single-precision floating-point value from xmm1/m32 to one signed quadword integer in r64. |
| SSE | CVTTSS2SI | r32, xmm1/m32 | F3 0F 2C /r | VEX.128.F3.0F.W0 2C /r | Convert one single-precision floating-point value from xmm1/m32 to one signed doubleword integer in r32 using truncation. |
| SSE | CVTTSS2SI | r64, xmm1/m32 | F3 REX.W 0F 2C /r | VEX.128.F3.0F.W1 2C /r | Convert one single-precision floating-point value from xmm1/m32 to one signed quadword integer in r64 using truncation. |
| SSE | LDMXCSR | m32 | 0F AE /2 | VEX.LZ.0F.WIG AE /2 | Load MXCSR register from m32. |
| SSE | MOVAPS | xmm1, xmm2/m128 | 0F 28 /r | VEX.128.0F.WIG 28 /r | Move aligned packed single-precision floating-point values from xmm2/mem to xmm1. |
| SSE | MOVAPS | xmm2/m128, xmm1 | 0F 29 /r | VEX.128.0F.WIG 28 /r | Move aligned packed single-precision floating-point values from xmm1 to xmm2/mem. |
| SSE | MOVHPS | m64, xmm1 | 0F 17 /r | VEX.128.0F.WIG 17 /r | Move two packed single-precision floating-point values from high quadword of xmm to m64. |
| SSE | MOVLPS | 0F 13/r | 0F 13/r | VEX.128.0F.WIG 13/r | Move two packed single-precision floating-point values from low quadword of xmm1 to m64. |
| SSE | MOVMSKPS | reg, xmm | 0F 50 /r | VEX.128.0F.WIG 50 /r | Extract 4-bit sign mask from xmm2 and store in reg. The upper bits of r32 or r64 are zeroed. |
| SSE | MOVUPS | xmm1, xmm2/m128 | 0F 10 /r | VEX.128.0F.WIG 10 /r | Move unaligned packed single-precision floating-point from xmm2/mem to xmm1. |
| SSE | MOVUPS | xmm2/m128, xmm1 | 0F 11 /r | VEX.128.0F.WIG 11 /r | Move unaligned packed single-precision floating-point from xmm1 to xmm2/mem. |
| SSE | RCPPS | xmm1, xmm2/m128 | 0F 53 /r | VEX.128.0F.WIG 53 /r | Computes the approximate reciprocals of packed single-precision values in xmm2/mem and stores the results in xmm1. |
| SSE | RSQRTPS | xmm1, xmm2/m128 | 0F 52 /r | VEX.128.0F.WIG 52 /r | Computes the approximate reciprocals of the square roots of packed single-precision values in xmm2/mem and stores the results in xmm1. |
| SSE | SQRTPS | xmm1, xmm2/m128 | 0F 51 /r | VEX.128.0F.WIG 51 /r | Computes Square Roots of the packed single-precision floating-point values in xmm2/m128 and stores the result in xmm1. |
| SSE | STMXCSR | m32 | 0F AE /3 | VEX.LZ.0F.WIG AE /3 | Store contents of MXCSR register to m32. |
| SSE | UCOMISS | xmm1, xmm2/m32 | 0F 2E /r | VEX.128.0F.WIG 2E /r | Compare low single-precision floating-point values in xmm1 and xmm2/mem32 and set the EFLAGS flags accordingly. |
| SSE | PEXTRW | reg, xmm, imm8 | 66 0F C5 /r ib | VEX.128.66.0F.W0 C5 /r ib | Extract the word specified by imm8 from xmm and move it to reg, bits 15:0. Zero-extend the result. The upper bits of r64/r32 is filled with zeros. |
| SSE | PEXTRW | reg/m16, xmm, imm8 | 66 0F 3A 15 /r ib | VEX.128.66.0F3A.W0 15 /r ib | Extract a word integer value from xmm2 at the source word offset specified by imm8 into reg or m16. The upper bits of r64/r32 is filled with zeros. |
| SSE | PMOVMSKB | reg, xmm | 66 0F D7 /r | VEX.128.66.0F.WIG D7 /r | Move a byte mask of xmm to reg. The upper bits of r32 or r64 are zeroed |
| SSE | MOVNTPS | m128, xmm1 | 0F 2B /r | VEX.128.0F.WIG 2B /r | Move packed single-precision values xmm1 to mem using non-temporal hint. |
| SSE2 | COMISD | xmm1, xmm2/m64 | 66 0F 2F /r | VEX.128.66.0F.WIG 2F /r | Compare low double-precision floating-point values in xmm1 and xmm2/mem64 and set the EFLAGS flags accordingly. |
| SSE2 | CVTSD2SI | r32, xmm1/m64 | F2 0F 2D /r | VEX.128.F2.0F.W0 2D /r | Convert one double-precision floating-point value from xmm1/m64 to one signed doubleword integer r32. |
| SSE2 | CVTSD2SI | r64, xmm1/m64 | F2 REX.W 0F 2D /r | VEX.128.F2.0F.W1 2D /r | Convert one double-precision floating-point value from xmm1/m64 to one signed quadword integer sign-extended into r64. |
| SSE2 | CVTTSD2SI | r32, xmm1/m64 | F2 0F 2C /r | VEX.128.F2.0F.W0 2C /r | Convert one double-precision floating-point value from xmm1/m64 to one signed doubleword integer in r32 using truncation. |
| SSE2 | CVTTSD2SI | r64, xmm1/m64 | F2 REX.W 0F 2C /r | VEX.128.F2.0F.W1 2C /r | Convert one double-precision floating-point value from xmm1/m64 to one signed quadword integer in r64 using truncation. |
| SSE2 | CVTPD2PS | xmm1, xmm2/m128 | 66 0F 5A /r | VEX.128.66.0F.WIG 5A /r | Convert two packed double-precision floating-point values in xmm2/mem to two single-precision floating-point values in xmm1. |
| SSE2 | CVTPS2PD | xmm1, xmm2/m64 | 0F 5A /r | VEX.128.0F.WIG 5A /r | Convert two packed single-precision floating-point values in xmm2/m64 to two packed double-precision floating-point values in xmm1. |
| SSE2 | CVTPD2DQ | xmm1, xmm2/m128 | F2 0F E6 /r | VEX.128.F2.0F.WIG E6 /r | Convert two packed double-precision floating-point values in xmm2/mem to two signed doubleword integers in xmm1. |
| SSE2 | CVTTPD2DQ | xmm1, xmm2/m128 | 66 0F E6 /r | VEX.128.66.0F.WIG E6 /r | Convert two packed double-precision floating-point values in xmm2/mem to two signed doubleword integers in xmm1 using truncation. |
| SSE2 | CVTDQ2PD | xmm1, xmm2/m64 | F3 0F E6 /r | VEX.128.F3.0F.WIG E6 /r | Convert two packed signed doubleword integers from xmm2/mem to two packed double-precision floating-point values in xmm1. |
| SSE2 | CVTPS2DQ | xmm1, xmm2/m128 | 66 0F 5B /r | VEX.128.66.0F.WIG 5B /r | Convert four packed single-precision floating-point values from xmm2/mem to four packed signed doubleword values in xmm1. |
| SSE2 | CVTTPS2DQ | xmm1, xmm2/m128 | F3 0F 5B /r | VEX.128.F3.0F.WIG 5B /r | Convert four packed single-precision floating-point values from xmm2/mem to four packed signed doubleword values in xmm1 using truncation. |
| SSE2 | CVTDQ2PS | xmm1, xmm2/m128 | 0F 5B /r | VEX.128.0F.WIG 5B /r | Convert four packed signed doubleword integers from xmm2/mem to four packed single-precision floating-point values in xmm1. |
| SSE2 | MOVAPD | xmm1, xmm2/m128 | 66 0F 28 /r | VEX.128.66.0F.WIG 28 /r | Move aligned packed double-precision floating-point values from xmm2/mem to xmm |
| SSE2 | MOVAPD | xmm2/m128, xmm1 | 66 0F 29 /r | VEX.128.66.0F.WIG 29 /r | Move aligned packed double-precision floating-point values from xmm1 to xmm2/mem. |
| SSE2 | MOVHPD | m64, xmm1 | 66 0F 17 /r | VEX.128.66.0F.WIG 17 /r | Move double-precision floating-point value from high quadword of xmm1 to m64. |
| SSE2 | MOVLPD | m64, xmm1 | 66 0F 13/r | VEX.128.66.0F.WIG 13/r | Move double-precision floating-point value from low quadword of xmm1 to m64. |
| SSE2 | MOVMSKPD | reg, xmm | 66 0F 50 /r | VEX.128.66.0F.WIG 50 /r | Extract 2-bit sign mask from xmm and store in reg. The upper bits of r32 or r64 are filled with zeros. |
| SSE2 | MOVUPD | xmm1, xmm2/m128 | 66 0F 10 /r | VEX.128.66.0F.WIG 10 /r | Move unaligned packed double-precision floating-point from xmm2/mem to xmm |
| SSE2 | MOVUPD | xmm2/m128, xmm1 | 66 0F 11 /r | VEX.128.66.0F.WIG 11 /r | Move unaligned packed double-precision floating-point from xmm1 to xmm2/mem. |
| SSE2 | SQRTPD | xmm1, xmm2/m128 | 66 0F 51 /r | VEX.128.66.0F.WIG 51 /r | Computes Square Roots of the packed double-precision floating-point values in xmm2/m128 and stores the result in xmm1. |
| SSE2 | UCOMISD | xmm1, xmm2/m64 | 66 0F 2E /r | VEX.128.66.0F.WIG 2E /r | Compare low double-precision floating-point values in xmm1 and xmm2/mem64 and set the EFLAGS flags accordingly. |
| SSE2 | MOVD | xmm, r/m32 | 66 0F 6E /r | VEX.128.66.0F.W0 6E /r | Move doubleword from r/m32 to xmm. |
| SSE2 | MOVD | r/m32, xmm | 66 0F 7E /r | VEX.128.66.0F.W0 7E /r | Move doubleword from xmm to r/m32. |
| SSE2 | MOVQ | xmm, r/m64 | 66 REX.W 0F 6E /r | VEX.128.66.0F.W1 6E /r | Move quadword from r/m64 to xmm. |
| SSE2 | MOVQ | r/m64, xmm | 66 REX.W 0F 7E /r | VEX.128.66.0F.W0 7E /r | Move quadword from xmm register to r/m64. |
| SSE2 | MOVDQA | xmm1, xmm2/m128 | 66 0F 6F /r | VEX.128.66.0F.WIG 6F /r | Move aligned packed integer values from xmm2/mem to xmm1. |
| SSE2 | MOVDQA | xmm2/m128, xmm1 | 66 0F 7F /r | VEX.128.66.0F.WIG 7F /r | Move aligned packed integer values from xmm1 to xmm2/mem. |
| SSE2 | MOVDQU | xmm1, xmm2/m128 | F3 0F 6F /r | VEX.128.F3.0F.WIG 6F /r | Move unaligned packed integer values from xmm2/m128 to xmm1. |
| SSE2 | MOVDQU | xmm2/m128, xmm1 | F3 0F 7F /r | VEX.128.F3.0F.WIG 7F /r | Move unaligned packed integer values from xmm1 to xmm2/m128. |
| SSE2 | MOVQ | xmm1, xmm2/m64 | F3 0F 7E /r | VEX.128.F3.0F.WIG 7E /r | Move quadword from xmm2/mem64 to xmm1. |
| SSE2 | MOVQ | xmm2/m64, xmm1 | 66 0F D6 /r | VEX.128.66.0F.WIG D6 /r | Move quadword from xmm1 to xmm2/mem64. |
| SSE2 | PEXTRW | reg, xmm, imm8 | 66 0F C5 /r ib | VEX.128.66.0F.W0 C5 /r ib | Extract the word specified by imm8 from xmm and move it to reg, bits 15-0. The upper bits of r32 or r64 is zeroed. |
| SSE2 | PEXTRW | reg/m16, xmm, imm8 | 66 0F 3A 15 /r ib | VEX.128.66.0F3A.W0 15 /r ib | Extract the word specified by imm8 from xmm and copy it to lowest 16 bits of reg or m16. Zero-extend the result in the destination, r32 or r64. |
| SSE2 | PMOVMSKB | reg, xmm | 66 0F D7 /r | VEX.128.66.0F.WIG D7 /r | Move a byte mask of xmm to reg. The upper bits of r32 or r64 are zeroed. |
| SSE2 | PSHUFLW | xmm1, xmm2/m128, imm8 | F2 0F 70 /r ib | VEX.128.F2.0F.WIG 70 /r ib | Shuffle the low words in xmm2/m128 based on the encoding in imm8 and store the result in xmm1. |
| SSE2 | PSHUFHW | xmm1, xmm2/m128, imm8 | F3 0F 70 /r ib | VEX.128.F3.0F.WIG 70 /r ib | Shuffle the high words in xmm2/m128 based on the encoding in imm8 and store the result in xmm1. |
| SSE2 | PSHUFD | xmm1, xmm2/m128, imm8 | 66 0F 70 /r ib | VEX.128.66.0F.WIG 70 /r ib | Shuffle the doublewords in xmm2/m128 based on the encoding in imm8 and store the result in xmm1. |
| SSE2 | MASKMOVDQU | xmm1, xmm2 | 66 0F F7 /r | VEX.128.66.0F.WIG F7 /r | Selectively write bytes from xmm1 to memory location using the byte mask in xmm2. The default memory location is specified by DS:DI/EDI/RDI. |
| SSE2 | MOVNTPD | m128, xmm1 | 66 0F 2B /r | VEX.128.66.0F.WIG 2B /r | Move packed double-precision values in xmm1 to m128 using non-temporal hint. |
| SSE2 | MOVNTDQ | m128, xmm1 | 66 0F E7 /r | VEX.128.66.0F.WIG E7 /r | Move packed integer values in xmm1 to m128 using nontemporal hint. |
| SSE3 | LDDQU | xmm1, m128 | F2 0F F0 /r | VEX.128.F2.0F.WIG F0 /r | Load unaligned data from mem and return double quadword in xmm1. |
| SSE3 | MOVDDUP | xmm1, xmm2/m64 | F2 0F 12 /r | VEX.128.F2.0F.WIG 12 /r | Move double-precision floating-point value from xmm2/m64 and duplicate into xmm1. |
| SSE3 | MOVSHDUP | xmm1, xmm2/m128 | F3 0F 16 /r | VEX.128.F3.0F.WIG 16 /r | Move odd index single-precision floating-point values from xmm2/mem and duplicate each element into xmm1. |
| SSE3 | MOVSLDUP | xmm1, xmm2/m128 | F3 0F 12 /r | VEX.128.F3.0F.WIG 12 /r | Move even index single-precision floating-point values from xmm2/mem and duplicate each element into xmm1. |
| SSSE3 | PABSB | xmm1, xmm2/m128 | 66 0F 38 1C /r | VEX.128.66.0F38.WIG 1C /r | Compute the absolute value of bytes in xmm2/m128 and store UNSIGNED result in xmm1. |
| SSSE3 | PABSD | xmm1, xmm2/m128 | 66 0F 38 1E /r | VEX.128.66.0F38.WIG 1E /r | Compute the absolute value of 32-bit integers in xmm2/m128 and store UNSIGNED result in xmm1. |
| SSSE3 | PABSW | xmm1, xmm2/m128 | 66 0F 38 1D /r | VEX.128.66.0F38.WIG 1C /r | Compute the absolute value of 16-bit integers in xmm2/m128 and store UNSIGNED result in xmm1. |
| AESNI | AESIMC | xmm1, xmm2/m128 | 66 0F 38 DB /r | VEX.128.66.0F38.WIG DB /r | Perform the InvMixColumn transformation on a 128-bit round key from xmm2/m128 and store the result in xmm1. |
| AESNI | AESKEYGENASSIST | xmm1, xmm2/m128, imm8 | 66 0F 3A DF /r ib | VEX.128.66.0F3A.WIG DF /r ib | Assist in AES round key generation using an 8 bits Round Constant (RCON) specified in the immediate byte, operating on 128 bits of data specified in xmm2/m128 and stores the result in xmm1. |
| SSSE4.1 | EXTRACTPS | reg/m32, xmm1, imm8 | 66 0F 3A 17 /r ib | VEX.128.66.0F3A.WIG 17 /r ib | Extract one single-precision floating-point value from xmm1 at the offset specified by imm8 and store the result in reg or m32. Zero extend the results in 64-bit register if applicable. |
| SSSE4.1 | MOVNTDQA | xmm1, m128 | 66 0F 38 2A /r | VEX.128.66.0F38.WIG 2A /r | Move double quadword from m128 to xmm1 using nontemporal hint if WC memory type. |
| SSSE4.1 | PEXTRB | r/m8, xmm2, imm8 | 66 0F 3A 14 /r ib | VEX.128.66.0F3A.W0 14 /r ib | Extract a byte integer value from xmm2 at the source byte offset specified by imm8 into reg or m8. The upper bits of r32 or r64 are zeroed. |
| SSSE4.1 | PEXTRD | r/m32, xmm2, imm8 | 66 0F 3A 16 /r ib | VEX.128.66.0F3A.W0 16 /r ib | Extract a dword integer value from xmm2 at the source dword offset specified by imm8 into r/m32. |
| SSSE4.1 | PEXTRQ | r/m64, xmm2, imm8 | 66 REX.W 0F 3A 16 /r ib | VEX.128.66.0F3A.W1 16 /r ib | Extract a qword integer value from xmm2 at the source qword offset specified by imm8 into r/m64. |
| SSSE4.1 | PEXTRW | reg, xmm, imm8 | 66 0F C5 /r ib | VEX.128.66.0F.W0 C5 /r ib | Extract the word specified by imm8 from xmm and move it to reg, bits 15-0. The upper bits of r32 or r64 is zeroed. |
| SSSE4.1 | PEXTRW | reg/m16, xmm, imm8 | 66 0F 3A 15 /r ib | VEX.128.66.0F3A.W0 15 /r ib | Extract the word specified by imm8 from xmm and copy it to lowest 16 bits of reg or m16. Zero-extend the result in the destination, r32 or r64. |
| SSSE4.1 | PHMINPOSUW | xmm1, xmm2/m128 | 66 0F 38 41 /r | VEX.128.66.0F38.WIG 41 /r | Find the minimum unsigned word in xmm2/m128 and place its value in the low word of xmm1 and its index in the secondlowest word of xmm1. |
| SSSE4.1 | PMOVSXBD | xmm1, xmm2/m32 | 66 0f 38 21 /r | VEX.128.66.0F38.WIG 21 /r | Sign extend 4 packed 8-bit integers in the low 4 bytes of xmm2/m32 to 4 packed 32-bit integers in xmm1. |
| SSSE4.1 | PMOVSXBQ | xmm1, xmm2/m16 | 66 0f 38 22 /r | VEX.128.66.0F38.WIG 22 /r | Sign extend 2 packed 8-bit integers in the low 2 bytes of xmm2/m16 to 2 packed 64-bit integers in xmm1. |
| SSSE4.1 | PMOVSXBW | xmm1, xmm2/m64 | 66 0f 38 20 /r | VEX.128.66.0F38.WIG 20 /r | Sign extend 8 packed 8-bit integers in the low 8 bytes of xmm2/m64 to 8 packed 16-bit integers in xmm1. |
| SSSE4.1 | PMOVSXWD | xmm1, xmm2/m64 | 66 0f 38 23/r | VEX.128.66.0F38.WIG 23 /r | Sign extend 4 packed 16-bit integers in the low 8 bytes of xmm2/m64 to 4 packed 32-bit integers in xmm1. |
| SSSE4.1 | PMOVSXWQ | xmm1, xmm2/m32 | 66 0f 38 24 /r | VEX.128.66.0F38.WIG 24 /r | Sign extend 2 packed 16-bit integers in the low 4 bytes of xmm2/m32 to 2 packed 64-bit integers in xmm1. |
| SSSE4.1 | PMOVSXDQ | xmm1, xmm2/m64 | 66 0f 38 25 /r | VEX.128.66.0F38.WIG 25 /r | Sign extend 2 packed 32-bit integers in the low 8 bytes of xmm2/m64 to 2 packed 64-bit integers in xmm1. |
| SSSE4.1 | PMOVZXBD | xmm1, xmm2/m32 | 66 0f 38 31 /r | VEX.128.66.0F38.WIG 31 /r | Zero extend 4 packed 8-bit integers in the low 4 bytes of xmm2/m32 to 4 packed 32-bit integers in xmm1. |
| SSSE4.1 | PMOVZXBQ | xmm1, xmm2/m16 | 66 0f 38 32 /r | VEX.128.66.0F38.WIG 32 /r | Zero extend 2 packed 8-bit integers in the low 2 bytes of xmm2/m16 to 2 packed 64-bit integers in xmm1. |
| SSSE4.1 | PMOVZXBW | xmm1, xmm2/m64 | 66 0f 38 30 /r | VEX.128.66.0F38.WIG 30 /r | Zero extend 8 packed 8-bit integers in the low 8 bytes of xmm2/m64 to 8 packed 16-bit integers in xmm1. |
| SSSE4.1 | PMOVZXWD | xmm1, xmm2/m64 | 66 0f 38 33 /r | VEX.128.66.0F38.WIG 33 /r | Zero extend 4 packed 16-bit integers in the low 8 bytes of xmm2/m64 to 4 packed 32-bit integers in xmm1. |
| SSSE4.1 | PMOVZXWQ | xmm1, xmm2/m64 | 66 0f 38 34 /r | VEX.128.66.0F38.WIG 34 /r | Zero extend 2 packed 16-bit integers in the low 4 bytes of xmm2/m32 to 2 packed 64-bit integers in xmm1. |
| SSSE4.1 | PMOVZXDQ | xmm1, xmm2/m64 | 66 0f 38 35 /r | VEX.128.66.0F 38.WIG 35 /r | Zero extend 2 packed 32-bit integers in the low 8 bytes of xmm2/m64 to 2 packed 64-bit integers in xmm1. |
| SSSE4.1 | PTEST | xmm1, xmm2/m128 | 66 0F 38 17 /r | VEX.128.66.0F38.WIG 17 /r | Set ZF if xmm2/m128 AND xmm1 result is all 0s. Set CF if xmm2/m128 AND NOT xmm1 result is all 0s. |
| SSSE4.1 | ROUNDPD | xmm1, xmm2/m128, imm8 | 66 0F 3A 09 /r ib | VEX.128.66.0F3A.WIG 09 /r ib | Round packed double precision floating-point values in xmm2/m128 and place the result in xmm1. The rounding mode is determined by imm8. |
| SSSE4.1 | ROUNDPS | xmm1, xmm2/m128, imm8 | 66 0F 3A 08 /r ib | VEX.128.66.0F3A.WIG 08 /r ib | Round packed single precision floating-point values in xmm2/m128 and place the result in xmm1. The rounding mode is determined by imm8. |
| SSSE4.2 | PCMPESTRI | xmm1, xmm2/m128, imm8 | 66 0F 3A 61 /r ib | VEX.128.66.0F3A 61 /r ib | Perform a packed comparison of string data with explicit lengths, generating an index, and storing the result in ECX. |
| SSSE4.2 | PCMPESTRM | xmm1, xmm2/m128, imm8 | 66 0F 3A 60 /r ib | VEX.128.66.0F3A 60 /r ib | Perform a packed comparison of string data with explicit lengths, generating a mask, and storing the result in XMM0. |
| SSSE4.2 | PCMPISTRI | xmm1, xmm2/m128, imm8 | 66 0F 3A 63 /r ib | VEX.128.66.0F3A.WIG 63 /r ib | Perform a packed comparison of string data with implicit lengths, generating an index, and storing the result in ECX. |
| SSSE4.2 | PCMPISTRM | xmm1, xmm2/m128, imm8 | 66 0F 3A 62 /r ib | VEX.128.66.0F3A.WIG 62 /r ib | Perform a packed comparison of string data with implicit lengths, generating a mask, and storing the result in XMM0. |
Appendix B : AVX Only Instructions
The table below lists all the instructions (mostly AVX2) that can only be encoded with a VEX prefix. Table to Markdown
| Type | Mnemonic | Operands | VEX Encoding | Description |
|---|---|---|---|---|
| AVX | vzeroupper | VEX.128.0F.WIG 77 | Zero upper 128 bits of all YMM registers. | |
| AVX | vzeroall | VEX.128.0F.WIG 77 | Zero upper 128 bits of all YMM registers. | |
| AVX | vcvtph2ps | xmm1, xmm2/m64 | VEX.128.66.0F38.W0 13 /r | Convert four packed half precision (16-bit) floatingpoint values in xmm2/m64 to packed single-precision floating-point value in xmm1. |
| AVX | vpermd | ymm1, ymm2, ymm3/m256 | VEX.NDS.256.66.0F38.W0 36 /r | Permute doublewords in ymm3/m256 using indices in ymm2 and store the result in ymm1. |
| AVX | vpsrlvd | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 45 /r | Shift doublewords in xmm2 right by amount specified in the corresponding element of xmm3/m128 while shifting in 0s. |
| AVX | vpsravd | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 46 /r | Shift doublewords in xmm2 right by amount specified in the corresponding element of xmm3/m128 while shifting in 0s. |
| AVX | vpsllvd | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 47 /r | Shift doublewords in xmm2 left by amount specified in the corresponding element of xmm3/m128 while shifting in 0s. |
| AVX | vgatherdps | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W0 92 /r | Using dword indices specified in vm32x, gather single-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| AVX | vgatherqps | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W0 93 /r | Using qword indices specified in vm64x, gather single-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| AVX | ANDN | r32a, r32b, r/m32 | VEX.NDS.LZ.0F38.W0 F2 /r | Bitwise AND of inverted r32b with r/m32, store result in r32a. |
| AVX | BZHI | r32a, r/m32, r32b | VEX.NDS.LZ.0F38.W0 F5 /r | Zero bits in r/m32 starting with the position in r32b, write result to r32a. |
| AVX | BEXTR | r32a, r/m32, r32b | VEX.NDS.LZ.0F38.W0 F7 /r | Contiguous bitwise extract from r/m32 using r32b as control; store result in r32a. |
| AVX | SHLX | r32a, r/m32, r32b | VEX.NDS.LZ.66.0F38.W0 F7 /r | Shift r/m32 logically left with count specified in r32b. |
| AVX | PEXT | r32a, r32b, r/m32 | VEX.NDS.LZ.F3.0F38.W0 F5 /r | Parallel extract of bits from r32b using mask in r/m32, result is written to r32a |
| AVX | SARX | r32a, r/m32, r32b | VEX.NDS.LZ.F3.0F38.W0 F7 /r | Shift r/m32 arithmetically right with count specified in r32b. |
| AVX | PDEP | r32a, r32b, r/m32 | VEX.NDS.LZ.F2.0F38.W0 F5 /r | Parallel deposit of bits from r32b using mask in r/m32, result is written to r32a. |
| AVX | MULX | r32a, r32b, r/m32 | VEX.NDD.LZ.F2.0F38.W0 F6 /r | Unsigned multiply of r/m32 with EDX without affecting arithmetic flags. |
| AVX | SHRX | r32a, r/m32, r32b | VEX.NDS.LZ.F2.0F38.W0 F7 /r | Shift r/m32 logically right with count specified in r32b. |
| AVX | vpermilps | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 0C /r | Permute single-precision floating-point values in xmm2 using controls from xmm3/m128 and store result in xmm1. |
| AVX | vpermilps | xmm1, xmm2/m128, imm8 | VEX.128.66.0F3A.W0 04 /r ib | Permute single-precision floating-point values in xmm2/m128 using controls from imm8 and store result in xmm1. |
| AVX | vpermilpd | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 0D /r | Permute double-precision floating-point values in xmm2 using controls from xmm3/m128 and store result in xmm1. |
| AVX | vpermilpd | xmm1, xmm2/m128, imm8 | VEX.128.66.0F3A.W0 05 /r ib | Permute double-precision floating-point values in xmm2/m128 using controls from imm8. |
| AVX | vtestps | xmm1, xmm2/m128 | VEX.128.66.0F38.W0 0E /r | Set ZF and CF depending on sign bit AND and ANDN of packed single-precision floating-point sources. |
| AVX | vtestpd | xmm1, xmm2/m128 | VEX.128.66.0F38.W0 0F /r | Set ZF and CF depending on sign bit AND and ANDN of packed double-precision floating-point sources. |
| AVX | vbroadcastss | xmm1, m32 | VEX.128.66.0F38.W0 18 /r | Broadcast double-precision floating-point element in mem to four locations in ymm1. |
| AVX | vbroadcastsd | ymm1, m64 | VEX.256.66.0F38.W0 19 /r | Broadcast double-precision floating-point element in mem to four locations in ymm1. |
| AVX | vbroadcastf128 | ymm1, m128 | VEX.256.66.0F38.W0 1A /r | Broadcast 128 bits of floating-point data in mem to low and high 128-bits in ymm1. |
| AVX | vmaskmovps | xmm1, xmm2, m128 | VEX.NDS.128.66.0F38.W0 2C /r | Conditionally load packed single-precision values from m128 using mask in xmm2 and store in xmm1. |
| AVX | vmaskmovpd | xmm1, xmm2, m128 | VEX.NDS.128.66.0F38.W0 2D /r | Conditionally load packed double-precision values from m128 using mask in xmm2 and store in xmm1. |
| AVX | vmaskmovps | m128, xmm1, xmm2 | VEX.NDS.128.66.0F38.W0 2E /r | Conditionally store packed single-precision values from xmm2 using mask in xmm1. |
| AVX | vmaskmovpd | m128, xmm1, xmm2 | VEX.NDS.128.66.0F38.W0 2F /r | Conditionally store packed double-precision values from xmm2 using mask in xmm1. |
| AVX | vpbroadcastd | xmm1, xmm2/m32 | VEX.128.66.0F38.W0 58 /r | Broadcast a dword integer in the source operand to four locations in xmm1. |
| AVX | vpbroadcastq | xmm1, xmm2/m64 | VEX.128.66.0F38.W0 59 /r | Broadcast a qword element in source operand to two locations in xmm1. |
| AVX | vbroadcasti128 | ymm1, m128 | VEX.256.66.0F38.W0 5A /r | Broadcast 128 bits of integer data in mem to low and high 128-bits in ymm1. |
| AVX | vpbroadcastb | xmm1, xmm2/m8 | VEX.128.66.0F38.W0 78 /r | Broadcast a byte integer in the source operand to sixteen locations in xmm1. |
| AVX | vpbroadcastw | xmm1, xmm2/m16 | VEX.128.66.0F38.W0 79 /r | Broadcast a word integer in the source operand to eight locations in xmm1. |
| AVX | vpmaskmovd | xmm1, xmm2, m128 | VEX.NDS.128.66.0F38.W0 8C /r | Conditionally load dword values from m128 using mask in xmm2 and store in xmm1. |
| AVX | vpmaskmovd | m128, xmm1, xmm2 | VEX.NDS.128.66.0F38.W0 8E /r | Conditionally store dword values from xmm2 using mask in xmm1. |
| AVX | vpmaskmovq | xmm1, xmm2, m128 | VEX.NDS.128.66.0F38.W1 8C /r | Conditionally load qword values from m128 using mask in xmm2 and store in xmm1. |
| AVX | vpmaskmovq | m128, xmm1, xmm2 | VEX.NDS.128.66.0F38.W1 8E /r | Conditionally store qword values from xmm2 using mask in xmm1. |
| AVX | vpermq | ymm1, ymm2/m256, imm8 | VEX.256.66.0F3A.W1 00 /r ib | Permute qwords in ymm2/m256 using indices in imm8 and store the result in ymm1. |
| AVX | vpermpd | ymm1, ymm2/m256, imm8 | VEX.256.66.0F3A.W1 01 /r ib | Permute double-precision floating-point elements in ymm2/m256 using indices in imm8 and store the result in ymm1. |
| AVX | vpblendd | xmm1, xmm2, xmm3/m128, imm8 | VEX.NDS.128.66.0F3A.W0 02 /r ib | Select dwords from xmm2 and xmm3/m128 from mask specified in imm8 and store the values into xmm1. |
| AVX | vpermilps | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 0C /r | Permute single-precision floating-point values in xmm2 using controls from xmm3/m128 and store result in xmm1. |
| AVX | vpermilps | xmm1, xmm2/m128, imm8 | VEX.128.66.0F3A.W0 04 /r ib | Permute single-precision floating-point values in xmm2/m128 using controls from imm8 and store result in xmm1. |
| AVX | vpermilpd | xmm1, xmm2, xmm3/m128 | VEX.NDS.128.66.0F38.W0 0D /r | Permute double-precision floating-point values in xmm2 using controls from xmm3/m128 and store result in xmm1. |
| AVX | vpermilpd | xmm1, xmm2/m128, imm8 | VEX.128.66.0F3A.W0 05 /r ib | Permute double-precision floating-point values in xmm2/m128 using controls from imm8. |
| AVX | vperm2f128 | ymm1, ymm2, ymm3/m256, imm8 | VEX.NDS.256.66.0F3A.W0 06 /r ib | Permute 128-bit floating-point fields in ymm2 and ymm3/mem using controls from imm8 and store result in ymm1. |
| AVX | vperm2i128 | ymm1, ymm2, ymm3/m256, imm8 | VEX.NDS.256.66.0F3A.W0 46 /r ib | Permute 128-bit integer data in ymm2 and ymm3/mem using controls from imm8 and store result in ymm1. |
| AVX | RORX | r32, r/m32, imm8 | VEX.LZ.F2.0F3A.W0 F0 /r ib | Rotate 32-bit r/m32 right imm8 times without affecting arithmetic flags. |
| AVX | vinsertf128 | ymm1, ymm2, xmm3/m128, imm8 | VEX.NDS.256.66.0F3A.W0 18 /r ib | Insert 128 bits of packed floating-point values from xmm3/m128 and the remaining values from ymm2 into ymm1. |
| AVX | vextractf128 | xmm1/m128, ymm2, imm8 | VEX.256.66.0F3A.W0 19 /r ib | Extract 128 bits of packed floating-point values from ymm2 and store results in xmm1/m128. |
| AVX | vcvtps2ph | xmm1/m64, xmm2, imm8 | VEX.128.66.0F3A.W0 1D /r ib | Convert four packed single-precision floating-point values in xmm2 to packed half-precision (16-bit) floating-point values in xmm1/m64. Imm8 provides rounding controls. |
| AVX | vinserti128 | ymm1, ymm2, xmm3/m128, imm8 | VEX.NDS.256.66.0F3A.W0 38 /r ib | Insert 128 bits of integer data from xmm3/m128 and the remaining values from ymm2 into ymm1. |
| AVX | vextracti128 | xmm1/m128, ymm2, imm8 | VEX.256.66.0F3A.W0 39 /r ib | Extract 128 bits of integer data from ymm2 and store results in xmm1/m128. |
| AVX | vblendvps | xmm1, xmm2, xmm3/m128, xmm4 | VEX.NDS.128.66.0F3A.W0 4A /r /is4 | Conditionally copy single-precision floating-point values from xmm2 or xmm3/m128 to xmm1, based on mask bits in the specified mask operand, xmm4. |
| AVX | vblendvpd | xmm1, xmm2, xmm3/m128, xmm4 | VEX.NDS.128.66.0F3A.W0 4B /r /is4 | Conditionally copy double-precision floating-point values from xmm2 or xmm3/m128 to xmm1, based on mask bits in the mask operand, xmm4. |
| AVX | vpblendvb | xmm1, xmm2, xmm3/m128, xmm4 | VEX.NDS.128.66.0F3A.W0 4C /r /is4 | Select byte values from xmm2 and xmm3/m128 using mask bits in the specified mask register, xmm4, and store the values into xmm1. |
Appendix C : VSIB Instructions
The table below list all the AVX instructions encoded with a VEX prefix that do use a VSIB.
| Mnemonic | Operands | VEX Encoding | Description |
|---|---|---|---|
| VGATHERDPD | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W1 92 /r | Using dword indices specified in vm32x, gather double-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VGATHERQPD | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W1 93 /r | Using qword indices specified in vm64x, gather double-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VGATHERDPS | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W0 92 /r | Using dword indices specified in vm32x, gather single-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VGATHERQPS | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W0 93 /r | Using qword indices specified in vm64x, gather single-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERDD | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W0 90 /r | Using dword indices specified in vm32x, gather dword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERQD | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W0 91 /r | Using qword indices specified in vm64x, gather dword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERDQ | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W1 90 /r | Using dword indices specified in vm32x, gather qword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERQQ | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W1 91 /r | Using qword indices specified in vm64x, gather qword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
Appendix D : VEX.vvvv Has Destination Operand Instructions
The table below list all the AVX instructions that are using the VEX[vvvv] bit field to define a destination operand.
| Mnemonic | Operands | VEX Encoding | Description |
|---|---|---|---|
| BLSI | r32, r/m32 | VEX.NDD.LZ.0F38.W0 F3 /3 | Extract lowest set bit from r/m32 and set that bit in r32. |
| BLSMSK | r32, r/m32 | VEX.NDD.LZ.0F38.W0 F3 /2 | Set all lower bits in r32 to “1” starting from bit 0 to lowest set bit in r/m32. |
| BLSR | r32, r/m32 | VEX.NDD.LZ.0F38.W0 F3 /1 | Reset lowest set bit of r/m32, keep all other bits of r/m32 and write result to r32. |
| VPSLLDQ | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 73 /7 ib | Shift xmm2 left by imm8 bytes while shifting in 0s and store result in xmm1. |
| VPSLLW | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 71 /6 ib | Shift words in xmm2 left by imm8 while shifting in 0s. |
| VPSLLD | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 72 /6 ib | Shift doublewords in xmm2 left by imm8 while shifting in 0s. |
| VPSLLQ | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 73 /6 ib | Shift quadwords in xmm2 left by imm8 while shifting in 0s. |
| VPSRAW | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 71 /4 ib | Shift words in xmm2 right by imm8 while shifting in sign bits. |
| VPSRAD | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 72 /4 ib | Shift doublewords in xmm2 right by imm8 while shifting in sign bits. |
| VPSRLDQ | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 73 /3 ib | Shift xmm2 right by imm8 bytes while shifting in 0s. |
| VPSRLW | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 71 /2 ib | Shift words in xmm2 right by imm8 while shifting in 0s. |
| VPSRLD | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 72 /2 ib | Shift doublewords in xmm2 right by imm8 while shifting in 0s. |
| VPSRLQ | xmm1, xmm2, imm8 | VEX.NDD.128.66.0F.WIG 73 /2 ib | Shift quadwords in xmm2 right by imm8 while shifting in 0s. |
Appendix E : VEX.vvvv Has Third Operand
The table below list all the AVX instructions that are using the VEX[vvvv] bit field to define a second source operand (3rd operand).
| Mnemonic | Operands | VEX Encoding | Description |
|---|---|---|---|
| BEXTR | r32a, r/m32, r32b | VEX.NDS.LZ.0F38.W0 F7 /r | Contiguous bitwise extract from r/m32 using r32b as control; store result in r32a. |
| BZHI | r32a, r/m32, r32b | VEX.NDS.LZ.0F38.W0 F5 /r | Zero bits in r/m32 starting with the position in r32b, write result to r32a. |
| SARX | r32a, r/m32, r32b | VEX.NDS.LZ.F3.0F38.W0 F7 /r | Shift r/m32 arithmetically right with count specified in r32b. |
| SHLX | r32a, r/m32, r32b | VEX.NDS.LZ.66.0F38.W0 F7 /r | Shift r/m32 logically left with count specified in r32b. |
| SHRX | r32a, r/m32, r32b | VEX.NDS.LZ.F2.0F38.W0 F7 /r | Shift r/m32 logically right with count specified in r32b. |
| VGATHERDPD | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W1 92 /r | Using dword indices specified in vm32x, gather double-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VGATHERQPD | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W1 93 /r | Using qword indices specified in vm64x, gather double-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VGATHERDPS | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W0 92 /r | Using dword indices specified in vm32x, gather single-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VGATHERQPS | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W0 93 /r | Using qword indices specified in vm64x, gather single-precision FP values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERDD | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W0 90 /r | Using dword indices specified in vm32x, gather dword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERQD | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W0 91 /r | Using qword indices specified in vm64x, gather dword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERDQ | xmm1, vm32x, xmm2 | VEX.DDS.128.66.0F38.W1 90 /r | Using dword indices specified in vm32x, gather qword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
| VPGATHERQQ | xmm1, vm64x, xmm2 | VEX.DDS.128.66.0F38.W1 91 /r | Using qword indices specified in vm64x, gather qword values from memory conditioned on mask specified by xmm2. Conditionally gathered elements are merged into xmm1. |
Appendix F: WIB Instructions
The table below list all the AVX instructions that silently ignore the VEX[W] bit when encoded with a 3-byte VEX prefix.